Universal Music Data Parser for 20+ Platforms

The Problem: Data Chaos in Music Industry
It was 2023 when we first sat down with a UK music label facing a common but frustrating problem. Every month, they received royalty reports from their distributors - ADA (Warner), The Orchard (Sony), Merlin, FUGA, Bandcamp, and a dozen others. Each report contained the same basic information: how many times their artists' songs were streamed, and how much money they earned.
ADA sent Excel files with columns named "Release Artist", "Release Title", and "Net Payable". Merlin called them "Artist name", "Track name", and "Payable". The Orchard went with "Artist Name", "Track Name", and "Label Share Net Receipts".
Same data. Different languages.
And that was just the beginning.
The Date Format Nightmare
Consider how different distributors format dates:
| Distributor | Date Format | Example |
|---|---|---|
| ADA | Excel serial number | 45292 |
| ADA (variant) | YYYYMM integer | 202501 |
| The Orchard | "YYYYMNN" | "2025M01" |
| Merlin | Hidden in metadata cells | Row 1, Column B |
| Qello | Embedded in filename | Qello_20250101_20250331.xlsx |
| Believe | ISO date string | "2025-01-15" |
One distributor. Four date formats. And we had 20+ distributors to support.
The Currency Problem
Some distributors report in USD. Others in EUR, GBP, or the original local currency. Some files contain mixed currencies. Some hardcode "USD" even when the actual currency varies by territory.
The "Same But Different" Problem
"UNITED STATES" vs "USA" vs "US" vs "United States of America". All the same country. All different strings that need to be normalized.
"Sony Music" vs "SONY" vs "Sony Music Entertainment" vs "SME". Same label. Four different spellings across different platforms.
The Solution: Adapter Pattern with Field Mapping
We needed a system that could:
- Accept any file format (CSV, XLS, XLSX, XLSB)
- Map arbitrary column names to a standard schema
- Handle date parsing edge cases per distributor
- Normalize currencies, countries, and entity names
- Scale to hundreds of millions of records
The Architecture
At its core, the system uses the Adapter Pattern - a universal base class that handles all common operations, with specialized adapters for each distributor that define only what's different:
- Base SDLImporter - handles file parsing, chunked processing, country normalization, currency conversion, and Elasticsearch indexing
- Distributor Adapters - each adapter contains only a field mapping dictionary and any date/currency parsing overrides specific to that distributor
class ADAAdapter(BaseSDLImporter):
FIELD_MAP = {
"Release Artist": "artist",
"Release Title": "track",
"Net Payable": "income",
}
def parse_date(self, raw):
# ADA uses Excel serial numbers
return excel_serial_to_date(raw)
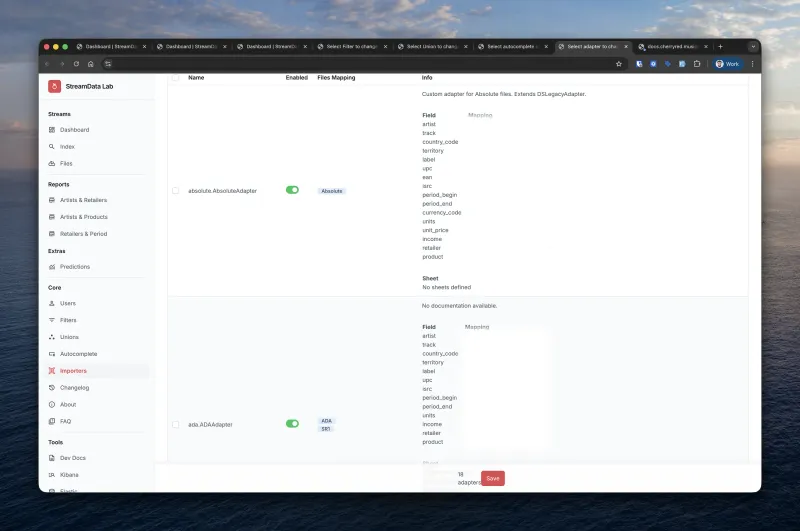
Supported Distributors and Adapters
We currently support 25+ adapters covering the major music distribution ecosystem:
Major Distributors
| Distributor | Parent Company | Adapter Variants |
|---|---|---|
| ADA | Warner Music | 5 adapters (Standard, V2, V2Fix, XLS, Custom) |
| The Orchard | Sony Music | 2 adapters (Standard, Legacy) |
| Merlin | Independent | 2 adapters (Standard, Historical) |
| FUGA | Downtown Music | 1 adapter |
| Believe | Independent | 2 adapters (Standard, Legacy) |
| TuneCore | Believe | 1 adapter |
| DistroKid | Independent | 1 adapter |
| CD Baby | Downtown Music | 1 adapter |
Specialized Platforms
| Platform | Type | Notes |
|---|---|---|
| Bandcamp | Direct-to-fan | Custom CSV format |
| Qello | Concert streaming | Date embedded in filename |
| Soundcloud | Streaming | Multiple report types |
| YouTube Music | Streaming | Content ID integration |
| TikTok | Social/UGC | Emerging format |
| Meta (Facebook/Instagram) | Social | Rights manager exports |
Regional Distributors
- Phonofile (Nordic region)
- Zebralution (Germany)
- IDOL (France)
- Altafonte (Spain/Latin America)
Supported File Formats
The system handles every file format encountered in the music distribution industry:
| Format | Extension | Use Case | Notes |
|---|---|---|---|
| CSV | .csv | Most common | UTF-8 and ISO-8859-1 encoding support |
| Excel | .xlsx | Standard Excel | openpyxl with read-only mode |
| Excel Binary | .xlsb | Large files | pyxlsb parser, common for 500K+ rows |
| Legacy Excel | .xls | Older systems | xlrd parser |
| TSV | .tsv | Some APIs | Tab-separated values |
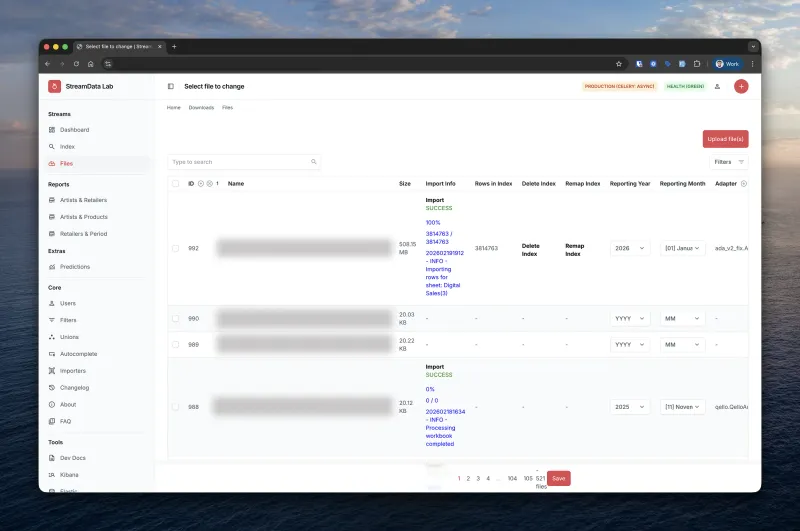
File Format Quirks We Handle
- XLS files containing CSV data - The Orchard and ADA sometimes send .xls files that are actually CSV
- Mixed encodings - Automatic fallback from UTF-8 to ISO-8859-1
- Files with metadata headers - Skip non-data rows (Merlin stores dates in row 1)
- Multi-sheet workbooks - Automatic sheet detection
Scale: 200 Million Records and Growing
Our production system currently manages:
200M+ Streaming records
25+ Active adapters
50+ File format variations
5-10M New records/month
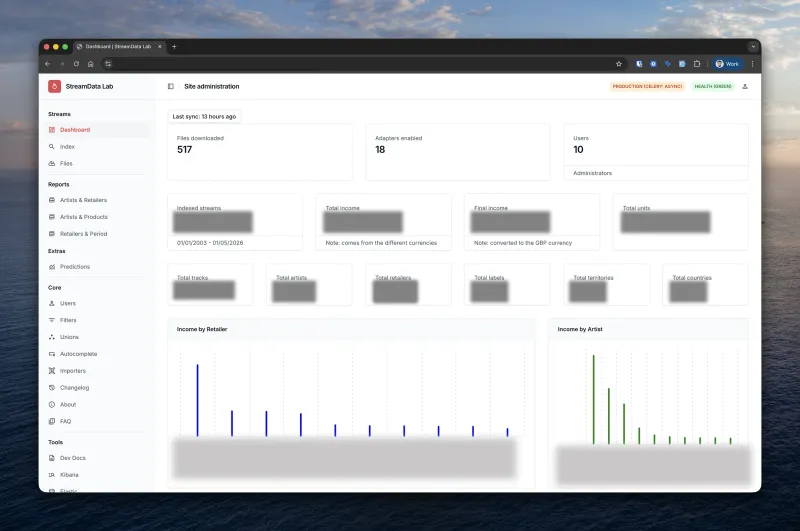
Performance Metrics
| Operation | Performance |
|---|---|
| Single file import (500K rows) | 2-3 minutes |
| Report generation | 5-15 seconds |
| Full-text search across catalog | Sub-second |
| Dashboard aggregations | Real-time |
The ability to generate complex royalty reports across 200 million records in just a few seconds is what sets the system apart. This is achieved through:
- Elasticsearch for aggregations and full-text search
- Pre-computed rollups for common report dimensions
- Chunked async processing during import (2000 rows per batch)
- Celery task queues for parallel processing
The 20 Standard Fields
After analyzing dozens of distributor formats, we defined a universal schema that captures all essential royalty data:
| Category | Fields |
|---|---|
| Identification | Artist, Track, Product (album), Label, UPC, EAN, ISRC |
| Location | Country code (ISO), Territory name |
| Time Period | Year, Month, Period begin/end dates |
| Financial | Currency, Units (streams/downloads), Unit price, Income, Income type (GROSS/NET) |
| Platform | Retailer (Spotify, Apple Music, etc.), Service type (streaming, download, sync) |
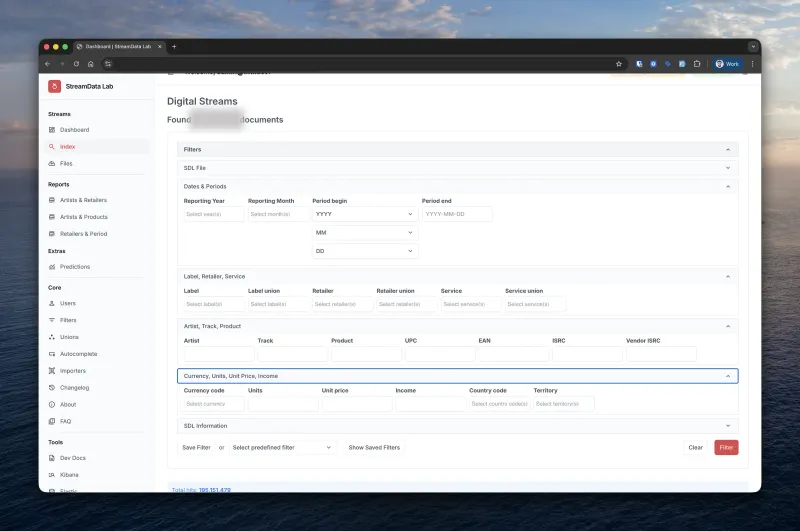
Real-World Challenges We Solved
The ADA Complexity
ADA (Warner's distribution arm) required 5 different adapters due to format inconsistencies:
| # | Adapter | Reason |
|---|---|---|
| 1 | Standard | Current production format |
| 2 | V2 | New format introduced in 2024 |
| 3 | V2Fix | Edge case corrections for V2 |
| 4 | XLS | Legacy .xls format |
| 5 | Custom | .xls files that actually contain CSV data |
Entity Resolution
We maintain mapping databases to normalize inconsistent naming:
"SME" → "Sony Music Entertainment"
"SPOTIFY AB" → "Spotify"
"UNITED KINGDOM (GB)" → "GB"
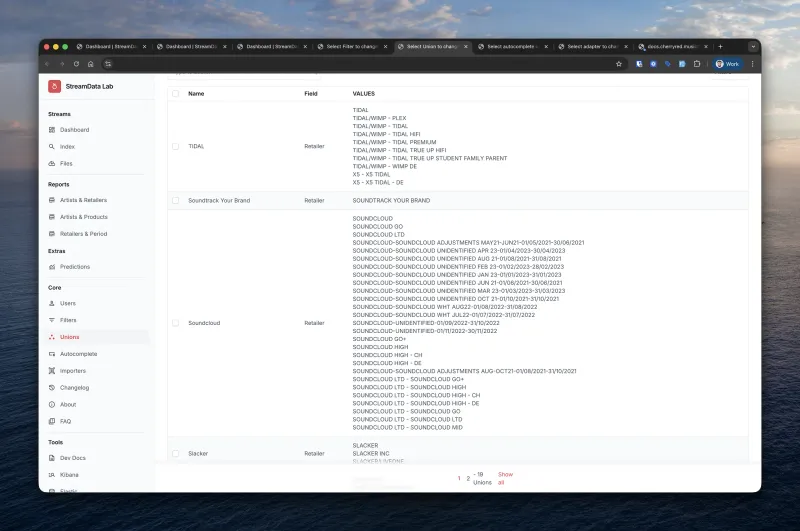
Encoding and Format Detection
Every file goes through automatic format detection and encoding fallback — because "just UTF-8" is never the reality in international music data.
Technologies Used
Python Backend
Elasticsearch Search & aggregations
Celery + Redis Async processing
PostgreSQL Relational storage
Docker Containerization
Digital Ocean Infrastructure
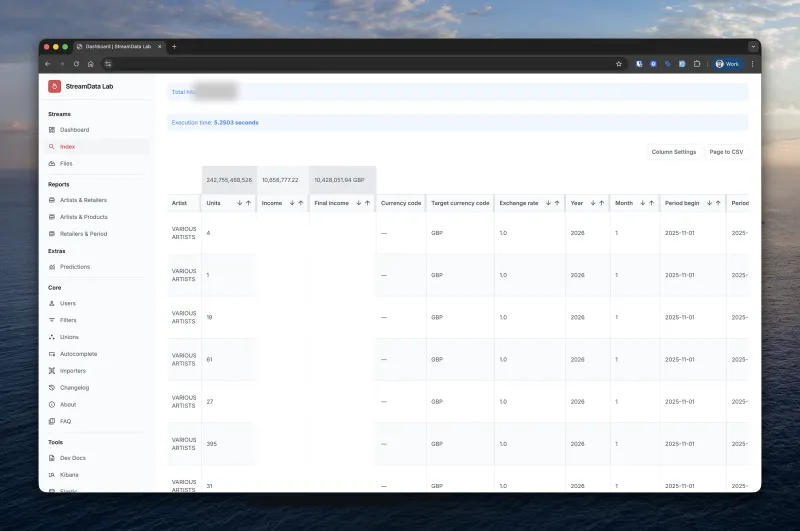
Results
After 18 months of development:
- 200 million records processed and searchable
- 25+ adapters for major music distributors
- Report generation in 5-15 seconds regardless of data volume
- Sub-second search across the entire catalog
- Zero manual data entry - fully automated pipeline
Development in Numbers
Building a system of this complexity doesn't happen overnight. Here's what the development effort looked like behind the scenes:
727 Commits
1,500+ Files created
84 Active development days
103 Peak commits in a single week
The development followed an intense sprint delivery model — 80% of all commits landed within a focused 3-month window (December 2024 – February 2025), averaging nearly 9 commits per active day. Each distributor adapter went through multiple iterations: for every new feature shipped, approximately 3 follow-up fixes were committed to handle real-world edge cases in date parsing, encoding, and field normalization.
This iterative approach — build, import real data, discover edge cases, fix, repeat — was essential. Music distribution data is messy by nature, and no amount of upfront design can replace the feedback loop of processing actual royalty files from 20+ platforms.
What We Learned
- Start with abstraction, add workarounds later — The Adapter Pattern gave us a clean base, but real-world data required pragmatic hacks.
- Date parsing is always harder than you think — We encountered formats we never imagined existed.
- Entity resolution is a feature, not a bug — Union mapping became one of the most valuable features for reporting.
- Scale matters from day one — Designing for millions of records upfront saved us from painful rewrites.
What's Next?
We're exploring:
- ClickHouse as the analytics engine - For the next project of this scale, we would replace Elasticsearch with ClickHouse for analytical queries. Its columnar storage and vectorized execution are purpose-built for aggregating billions of rows, offering significantly faster performance for royalty reporting workloads
- ML-based column mapping - Automatically detect field mappings for new distributors
- Real-time streaming ingestion - Move from batch files to API integrations
- Anomaly detection - Flag unusual patterns in royalty data
Let's Build Something Together
Have a similar project in mind? We'd love to hear about it.
Get in touch to discuss how we can help bring your vision to life.
4D Grupa Roofing Wholesalers Platform
How we built a scalable headless CMS platform in Sanity with TypeScript and Gridsome for Poland's largest roofing wholesalers network.
Talent Alpha HR Frontend Platform
How we augmented an HR startup's in-house team with frontend developers for Angular and React.js projects, delivering features on a tight deadline.