Batch ISRC Enrichment That Turns Messy Catalogs Into Clean Data

Key Takeaways
If you have ever opened a 40,000-row CSV and found half the ISRC codes missing, inconsistent, or flat-out wrong, you know the pain. Manually looking up each track via Spotify, MusicBrainz, or ISRC lookup tools takes days. We built Scout to do it in minutes.
The Problem Every Catalog Manager Knows
Track data arrives as CSV or Excel files. They contain track names, artist names, and sometimes ISRCs. The problem is that "sometimes" is doing a lot of heavy lifting in that sentence.
This is not a niche issue. Anyone doing soundtrack acquisition, catalog evaluation, royalty reconciliation, or building investor decks hits this wall. The data exists across multiple sources, but nobody connects it at scale.
A Real-World Example: Santana's "Smooth"
To show why this matters, take a concrete case. Santana's "Smooth" appears in a royalty report with ISRC USAT29900471. When Scout looks up the same track on Spotify, it comes back as USAR19900033.
Both are valid ISRCs for the same recording. The first is from the original 1999 Arista release, the second from a later digital distribution. This happens constantly in the music industry because every release edition (original, remaster, compilation, deluxe, single) can get its own ISRC.
Without automated enrichment, you would either miss this mismatch entirely or spend hours tracking it down manually. Multiply that by 40,000 rows and you understand why catalog managers describe this work as "soul-crushing."
What Scout Does
Scout is a feature inside MusicData Lab that batch-enriches track metadata from two authoritative sources: the Spotify API and the MusicBrainz API.
Upload and Map
Drop a CSV or Excel file. Scout auto-detects common column names (track, artist, ISRC, URL) and lets you adjust the mapping before processing.
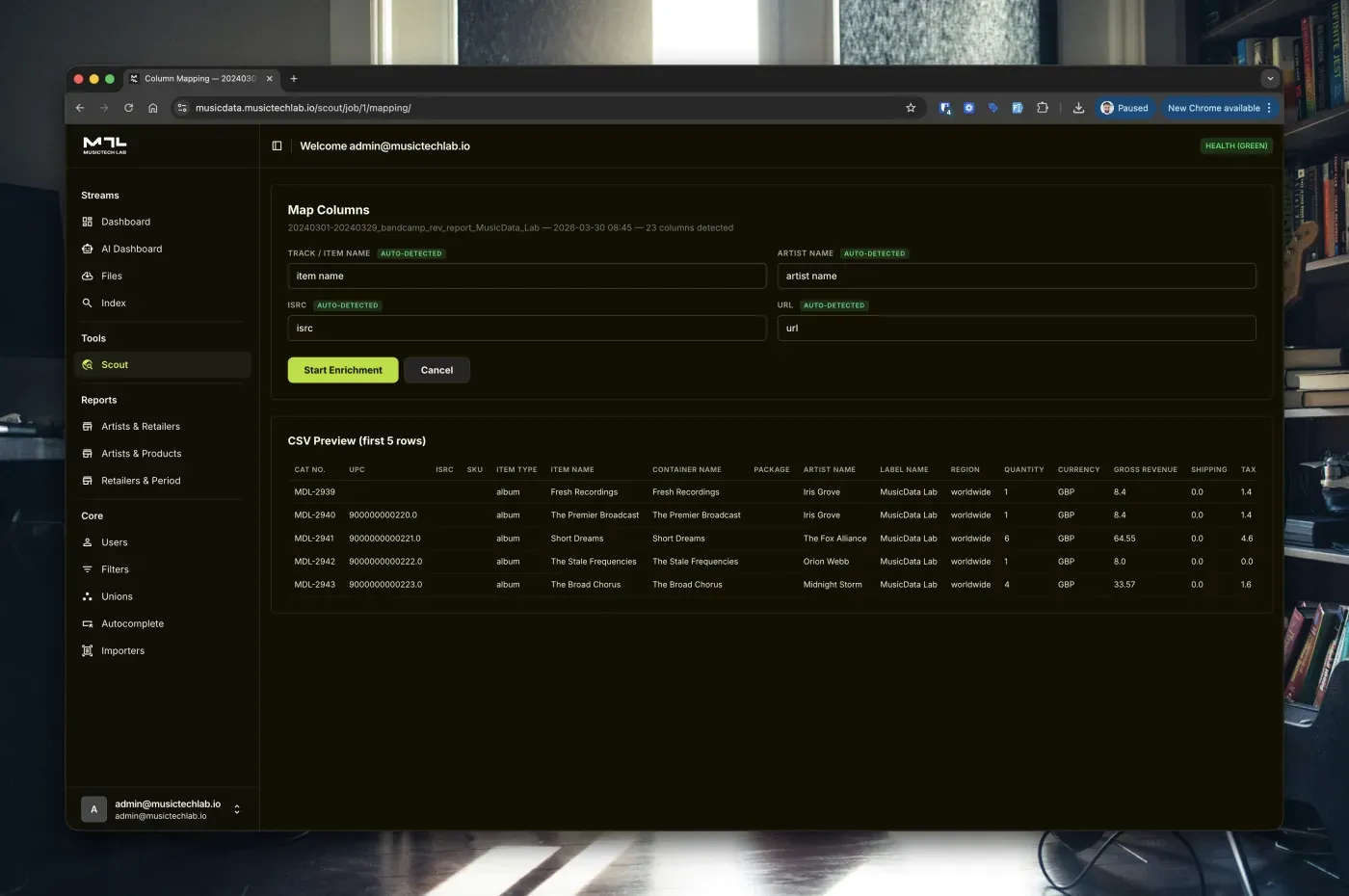
Enrich Every Track
For each row, Scout runs a four-stage lookup pipeline:
Loading diagram...
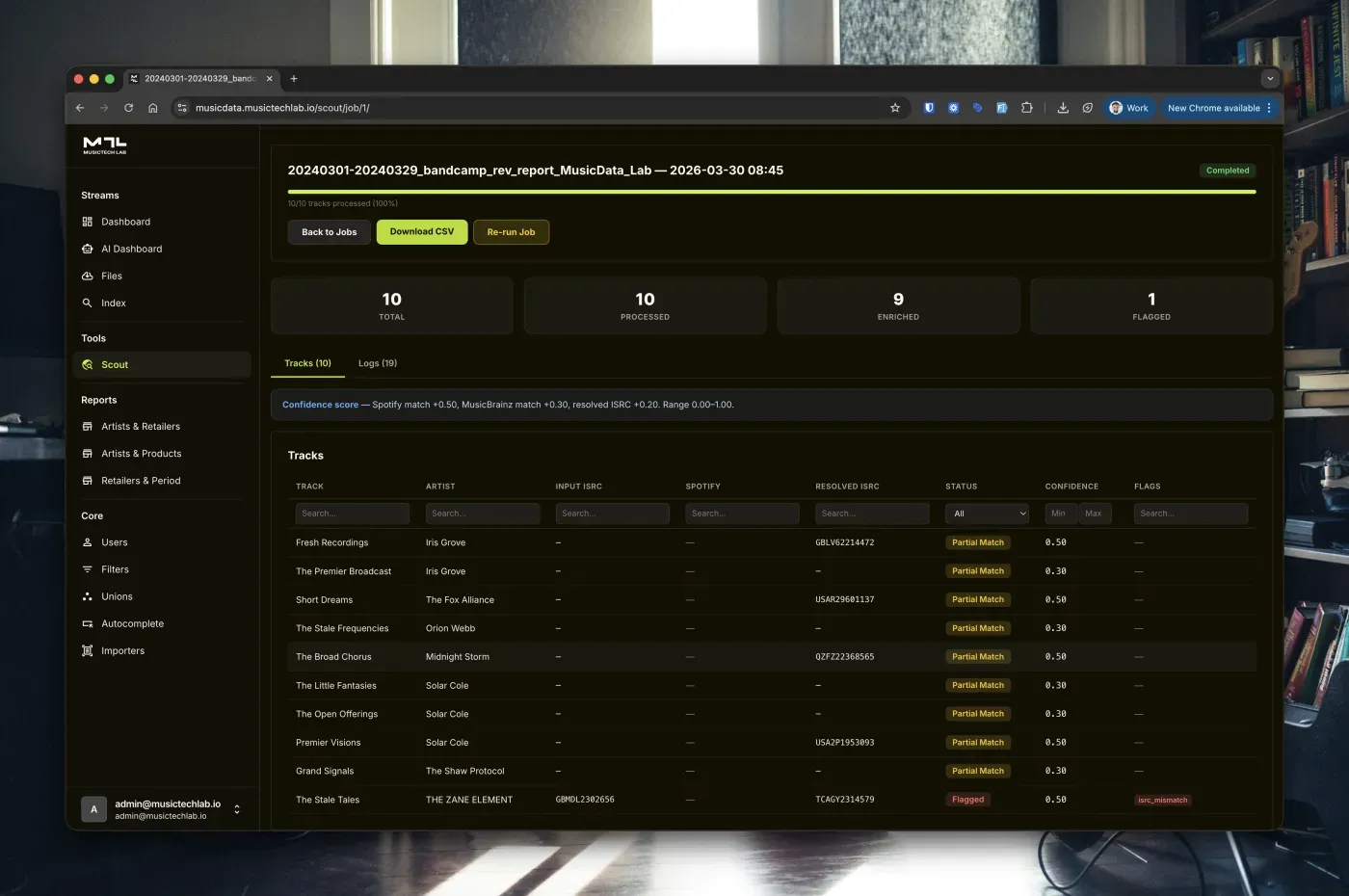
Confidence Scoring
Each track gets a confidence score from 0.00 to 1.00:
| Source | Score |
|---|---|
| Spotify match | +0.50 |
| MusicBrainz match | +0.30 |
| Resolved ISRC | +0.20 |
A track matched by both Spotify and MusicBrainz with a resolved ISRC scores a perfect 1.00. Flags are informational only. They tell you something needs attention without penalizing the match quality.
Export
When processing completes, download a clean CSV with all original data plus every enriched field: Spotify metadata, MusicBrainz metadata, resolved ISRCs, status, flags, and confidence scores. Ready for analysis, investor decks, or import into your rights management system.
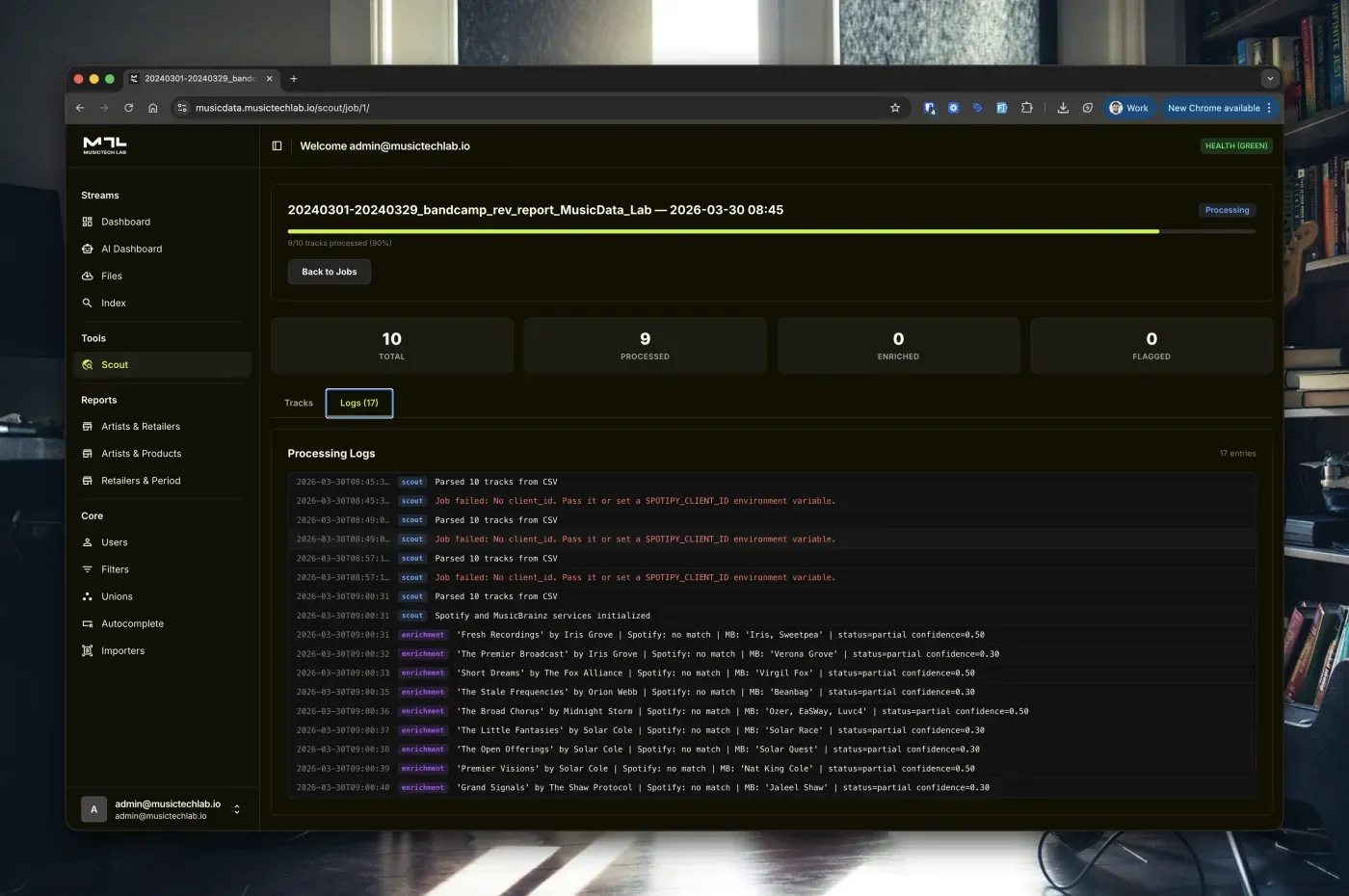
Processing at Scale
Scout processes files asynchronously using Celery workers. A 40,000-row file runs in the background while you continue working. The job detail page shows real-time progress without page refreshes:
The Flags That Matter
Scout raises four types of flags:
- isrc_mismatch - the input ISRC, Spotify ISRC, and MusicBrainz ISRC do not all agree. Most common flag. Usually means different release editions.
- artist_mismatch - the artist name from Spotify and MusicBrainz has a fuzzy match score below 75%. Can indicate featuring artists, name variations, or genuine data issues.
- duplicate_isrc - multiple rows in your file resolve to the same ISRC. Important for catching double-counted tracks.
- enrichment_error - the lookup failed for technical reasons (API timeout, rate limit, etc.).
isrc_mismatch to quickly review all tracks where your input ISRC differs from what Spotify and MusicBrainz report. These are your highest-priority reconciliation items.Why Public APIs Instead of DSP Bulk Feeds?
A reasonable question if you know the space: why use the public Spotify Web API and MusicBrainz, rather than a licensed DSP bulk feed?
The most well-known bulk feed is Apple's Enterprise Partner Feed (EPF) — daily metadata dumps of the full Apple Music catalog, delivered to approved partners (distributors, royalty processors, rights administrators). On the Spotify side, partner programs like Spotify Publishing Analytics give publishers and licensees access to stream, ISRC, and playlist data that the public Web API does not expose.
Scout uses the public APIs for two reasons:
- Bulk feeds require a signed partner agreement. Approval is gated to entities with a real B2B use case in distribution, publishing, or rights administration. Most catalog buyers and acquisition teams we work with do not hold one.
- For evaluation work, public APIs hit the same accuracy ceiling on ISRCs and core metadata. Bulk feeds win on scale and historical snapshots; for a one-off enrichment pass, the cross-check between Spotify and MusicBrainz already catches the issues that matter.
From Script to Product
The inspiration for Scout came from a real conversation with a music professional doing soundtrack acquisition work. They had built a Python script that batch-processed metadata from Spotify and MusicBrainz APIs using pandas. No AI needed, just API calls and data wrangling.
We took that exact workflow and productized it inside MusicData Lab:
Who This Is For
Scout is built for anyone who deals with music metadata at scale:
- Rights managers reconciling royalty statements across distributors
- A&R teams evaluating catalogs for acquisition
- Independent labels cleaning up their metadata before pitching to sync agents
- Royalty analysts spotting unclaimed revenue from ISRC gaps
- Catalog managers preparing clean data for investor decks or audits
If you are spending days in spreadsheets manually looking up ISRCs, Scout does that work for you and flags the problems worth your attention.
Let's Build Something Together
Have a similar project in mind? We'd love to hear about it.
Get in touch to discuss how we can help bring your vision to life.
Poland's Creative Tech and MusicTech Rise
Poland’s first Creative Tech report is here and MusicTech Lab’s Maciej Dulski shares insights on how music innovation in Poland is gaining momentum.
Music Self-Publishing: The Emuze.me Story
How self-publishing evolved in the music industry, shifting control from record labels to independent artists, and how Emuze.me empowers creators today.
Related Articles


Technical Partner
Technical partner at MusicTech Lab with 15+ years in software development. Builder, problem solver, blues guitarist, long-distance swimmer, and cyclist.
Newsletter
Get music tech insights, case studies, and industry news delivered to your inbox.